Методика тестирования качества серверных антиспам-фильтров
Введение При выборе антиспам-фильтра необходимо сопоставить:
--- стоимость, --- функциональность и удобство работы, --- качество распознавания спама. --- Оценка стоимости и функциональности может быть произведена даже умозрительно - по документации компании-производителя.
Ситуация же с качеством существенно сложнее - на сегодняшний день не существует не только каких-либо "стандартных" методик тестирования качества фильтрации спама, но и общепринятых подходов к такому тестированию. В результате, все тесты проводятся по разным методам, следовательно, результаты разных тестов невозможно сравнивать между собой. Это относится как к данным производителей антиспам-решений, так и к результатам независимых тестов.
В данном документе предлагается методика тестирования качества фильтрации спама, а также обсуждаются типичные ошибки, допускаемые при тестировании.
1. Определение спама При тестировании качества работы Антиспам-фильтра необходимо заранее определить понятие "спам"; без определения этого термина дальнейшая работа не имеет смысла.
При написании данного документа использовалось следующее определение:
Спам - это анонимные незапрошенные массовые рассылки электронной почты, как правило, имеющие рекламный характер.
Данное определение удовлетворительно определяет спам как массовые рекламные рассылки, производимые профессионалами для зарабатывания денег. А ровно от этого бизнеса сейчас и страдают все пользователи Интернета.
2. Нежелательная или ненужная почта В то же время, спамом в действительности не являются следующие виды сообщений (часть из них может быть массовой или нежелательной почтой):
--- Рассылки, на которые пользователь когда-то подписывался (даже если он уже не хочет ее получать и/или забыл, как отписаться). --- Рассылки, на которые пользователь подписывался неявно, например, включив (или забыв выключить) галочку "я хочу получать дополнительную информацию о продуктах компании N" при регистрации на Web-сайте компании или в анкете на выставке. --- Технические сообщения систем электронной почты, включая сообщения о недоставке писем, которые пользователь не рассылал (во время последних вирусных эпидемий такие случаи участились). --- Технические сообщения антивирусных систем о том, что в письме найден вирус. --- Уведомления о доставке, недоставке или прочтении писем получателем. --- Прочие не слишком нужные пользователю сообщения (например, сообщения о том, что в почтовой системе расширен лимит на хранение почты; информация о функционировании интернет-сервиса, которым пользуется пользователь и так далее). --- Единичные нежелательные сообщения, даже если они анонимны. --- Поздравительные открытки (которые, как правило, анонимны). --- Письма, посланные по ошибке. --- Вирусные сообщения и сообщения с "троянскими программами" - для них есть антивирусы. Однако, зачастую пользователи и системные администраторы считают подобные сообщения спамом (трактуя их расширительно - как "нежелательную корреспонденцию").
Другими словами, одно и то же письмо (с одинаковым текстом и технической информацией) может быть расценено как спам одними пользователями и как не-спам - другими. В то же время серверные антиспам-фильтры не могут делать предположений о пожеланиях получателей и вынуждены принимать решение о классификации только на основании технической информации и текста сообщения.
Таким образом, при тестировании антиспам-фильтров и при интерпретации результатов тестирования следует использовать единое для пользователей и тестировщиков определение спама, лучше всего - предложенное выше, и не засчитывать "нежелательную", но легитимную почту как спам.
3. Критерии оценки качества Для оценки качества работы антиспам-сервисов следует одновременно использовать два следующих критерия:
1. Ложные тревоги. Доля нормальных (не являющихся спамом) сообщений, ошибочно классифицированных как спам (ложные срабатывания или false positive), в общем потоке нормальной почты.
2. Пропуск спама. Доля пропущенного спама (или false negative) в общем потоке спама.
Обе характеристики нужно рассчитывать корректно, а именно:
1. Процент ложных тревог - это отношение числа нормальных писем, ошибочно признанных спамом, к количеству всей нормальной почты (пропущенных и заблокированных нормальных писем), а не от всего потока, включающего и спам тоже. Таким образом, 0,3% ложных тревог могут означать, например, что всего пришло 10 000 нормальных писем, и из них 30 было ошибочно признано спамом.
2. Процент пропусков - отношение количества пропущенного спама к объему всего спама (как пропущенного, так и распознанного). Таким образом, 15% пропусков (или 85% уровень фильтрации) означают, например, что всего пришло 10 000 спамовых писем, из которых 1500 не было распознано как спам.
3.1. Критические и некритические ложные срабатывания
В ситуациях, когда электронная почта является важным каналом коммуникации для компании, необходимо поддержание максимально низкой доли ложных срабатываний, особенно для важных деловых писем. Ущерб от потерянного делового письма может быть несопоставим с потерями рабочего времени от спама (это не означает, естественно, что спам вообще не нужно фильтровать).
При анализе ложных срабатываний недостаточно ограничиться только подсчетом их количества. В современных спам-фильтрах используются эвристические алгоритмы, которые могут распознать как спам (или "возможно спам") сообщения, "похожие на спам" (например, письмо всем пользователям интернет-магазина о скидках, написанное с использованием "маркетинговой лексики"), но при этом спамом с точки зрения получателей не являющиеся.
Целесообразно при тестировании разделить ложные срабатывания на критические ложные срабатывания (ложные срабатывания на важной деловой или личной почте) и некритические (ошибочная классификация массовых новостных и маркетинговых рассылок и тому подобной почты) и подсчитывать процент тех и других отдельно.
3.2 Пропущенный спам Критерий на основе доли "пропущенного спама" является наиболее очевидным - если один антиспам-фильтр распознает 70%, а второй - 85% спама, то второй фильтр можно считать лучшим. В то же время необходимо понимать, что повышение уровня распознавания может с большой вероятностью дать одновременный рост количества ложных срабатываний.
Поэтому оба критерия нужно рассматривать совместно, причем оценка количества ложных срабатываний должна иметь приоритет при составлении суммарной оценки фильтра.
3.3 Скорость реакции Очевидно, для любого пользователя наиболее важен не технический показатель качества распознавания спама, полученный в лабораторных условиях ("тестирование идеальной сферической лошади в вакууме"), а отсутствие спама в его почтовом ящике.
Современная спам-рассылка в несколько миллионов адресов обычно занимает несколько часов и впоследствии не повторяется. В следующий раз спамер посылает другие письма и с других адресов.
Это означает, что оба критерия качества (уровень распознавания и количество ложных тревог) имеют значение только в применении к реальному потоку спам-рассылок, идущих в настоящее время, прямо сейчас. Если же фильтр отлично распознает те же спам-рассылки, но спустя день-два или неделю, то такая фильтрация абсолютно неинтересна.
Таким образом, значение имеет только качество фильтрации реального потока спама в реальном времени, а тестировать следует скорость реакции фильтра на реальный поток спама.
Ниже в разделе "Ошибки тестирования" мы подробно показываем, почему тестирование на фиксированных коллекциях не имеет смысла.
4. Методика тестирования
А. Реальная эксплуатация на реальном потоке почты в реальном времени. Наиболее достоверные результаты тестирования антиспам-систем можно получить только на реальном потоке почты и только при фильтрации немедленно, в реальном времени.
Только в этом случае:
--- распределение почты по типам (спам/не спам и так далее) соответствует реальному; --- техническая информация в письмах (IP-адрес посылающей стороны, SMTP envelope, технические заголовки) соответствует реальному положению дел; --- содержимое баз данных фильтров (лингвистических, статистических, RBL-списков1, черных/белых списков отправителей) является актуальным; --- тексты писем не искажены за счет пересылки, вставки дополнительной информации или подобных действий; --- решается задача реальной фильтрации.
Б. Тестирование должно продолжаться как минимум 2-3 недели. Поток как спама, так и нормальной почты, сильно меняется во времени, обычно изменения тематики и оформления писем происходят ежедневно. Продолжительный тестовый период должен усреднить эти колебания. Полезно, если часть тестового периода может включить в себя сезонные изменения маркетинговой активности (предпраздничные распродажи, например) - это позволит оценить качество реакции антиспам-системы на пике спама.
В. При тестировании через систему должны пройти несколько десятков тысяч сообщений. В противном случае достоверно оценить уровень ложных срабатываний невозможно (так как приемлемый уровень некритических ложных срабатываний - не выше 0,01%, то есть одна ложная тревога на 10 тысяч писем или меньше).
Г. В тестировании должны принимать участие как минимум несколько десятков почтовых ящиков. Это требование определяется тем, что вариативность потока спама у разных пользователей очень велика. Например, на ящики с именами info@, sales@ или alex@ приходит много мусорной почты, так как подобные имена легко подбираются методом словарной атаки, а на ящики со сложными именами наподобие Joe.V.User@ спама приходит во много раз меньше (особенно, если эти длинные адреса публиковались в общедоступных местах).
Использование при тестировании большого числа почтовых ящиков позволяет усреднить вариации в потоках спама между различными типами почтовых ящиков.
Д. При тестировании нельзя пересылать (forward) почту. При пересылке искажается техническая информация, а в некоторых случаях и текст письма. В то же время, современные фильтры анализируют "письмо в целом" и искажение данных приведет к падению качества распознавания.
Е. Анализ результатов необходимо проводить с использованием единого определения спама и критичности/некритичности ложных срабатываний. Как пропуски спама, так и (в особенности) ложные срабатывания должны быть тщательно проанализированы. При оценке доли пропусков необходимо использовать корректное и единое для всех тестов определение спама (см. выше). При оценке ложных срабатываний следует учитывать их критичность, поскольку это принципиально для оценки рисков использования конкретного фильтра.
Ж. Равные условия тестирования. При сравнении нескольких решений от разных производителей, антиспам-фильтры должны быть поставлены в равные условия. Это включает в себя следующие требования:
--- Одинаковый поток почты, приходящий на разные фильтры в реальном времени. --- При использовании RBL-сервисов - одинаковый набор списков RBL для всех тестируемых систем. --- При использовании локальных черных/белых списков - использование одинаковых списков. --- При использовании обучаемых фильтров - обучение на одинаковых выборках. Если в процессе тестирования используется дообучение - дообучение должно быть синхронным/по одним и тем же выборкам. --- При использовании фильтров с получениями обновлений - синхронное получение обновлений. --- Все прочие "параллельные" наборы настроек (например: разбор заголовков для получения оттуда IP-адресов, использование распределенных систем DCC/Razor и так далее) - должны быть по возможности одинаковыми.
Сводка: цели и корректные условия тестирования
Таким образом, достоверные результаты тестирования можно получить при выполнении следующих необходимых условий:
--- Тестирование в реальном окружении (установка антиспам-фильтра на тот же поток почты, где его предполагается в дальнейшем использовать). --- Достаточная продолжительность тестирования - 2-3 недели. --- Достаточный объем тестирующей выборки - как минимум несколько тысяч сообщений в день. --- Достаточная выборка почтовых ящиков - как минимум несколько десятков. --- Анализ результатов с использованием корректного определения спама и категорий критичных/некритичных ложных срабатываний. --- Тестируемое ПО должно быть поставлено в максимально одинаковые условия.
5. Особенности тестирования отдельных видов фильтров
Помимо изложенной выше методики тестирования, применимой к любым антиспам-решениям, существует ряд особенностей конкретных способов фильтрации спама, которые стоит учитывать в схеме тестирования.
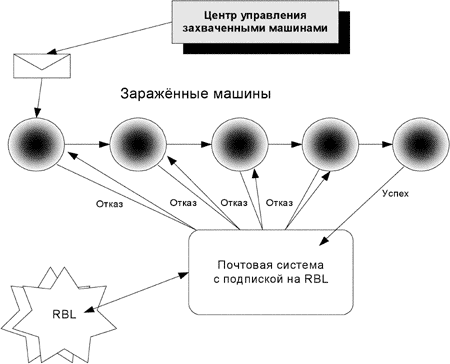
5.1 Фильтры, использующие черные списки (RBL) А. Оценка эффективности классических RBL-фильтров. Наиболее распространенным режимом использования RBL, поддержанным в большинстве почтовых серверов (MTA), является безусловное отвержение (reject) сообщений, приходящих с IP-адресов, содержащихся в RBL-списке. В таких случаях эффективность фильтра оценивают как отношение числа пропущенных спам-сообщений к числу отвергнутых писем. Однако современные спам-технологии предполагают перепосылку одного и того же сообщения с разных IP-адресов вплоть до успешной доставки на данный сервер (возможно, с ограничением числа попыток).
В этом случае одно и то же письмо может быть сначала несколько раз отвергнуто, а потом все-таки принято.
В таком случае с формальной точки зрения отношение количества прошедшего спама к числу отвергнутых сообщений - впечатляет (то есть фильтр кажется весьма эффективным), а на самом деле эффективность такого RBL-фильтра близка к нулевой.
Необходимо также отметить, что в RBL-фильтрах с отвержением почты не существует способа оценить долю ложных срабатываний, поскольку почтовый сервер вообще не принимает отвергнутое письмо и проверить его содержание постфактум невозможно.
Таким образом, статистика самого RBL-фильтра (особенно количество отвергнутых им писем) не очень показательна. Если есть возможность на одном и том же потоке сравнить количество посылаемого спама при включенном и отключенном RBL-фильтре, это обязательно нужно сделать.
Б. Необходимо тестирование RBL в реальном времени. RBL- базы данных реального времени: большая часть RBL-списков постоянно пополняется; столь же постоянно оттуда удаляются какие-то записи.
Таким образом, результаты анализа одного и того же набора сообщений будут изменяться во времени, следовательно, для оценки реального качества RBL-фильтров, тестирование в реальном времени совершенно необходимо.
В. Невозможность тестирования фильтра на основе RBL путем пересылки. Большинство RBL-фильтров использует реальный IP-адрес посылающей стороны - этот адрес невозможно подделать (в отличие от заголовков). Однако при дальнейшей пересылке сообщения этот адрес не сохраняется - таково свойство почтовой сессии.
Таким образом, тестируемый RBL-фильтр должен быть установлен на входном почтовом сервере (incoming mail relay) организации, а не после него.
5.2 Тестирование фильтров с регулярными обновлениями баз данных К часто обновляемым базам данных применимы те же ограничения, что и к RBL - это базы данных практически реального времени, так что для целей тестирования важно их состояние на момент прихода спам-сообщения. Дело в том, что сигнатуры спама могут как добавляться в базу данных, так и со временем удаляться оттуда по причине их устаревания.
Таким образом, при тестировании систем с обновлениями нужно соблюдать следующие условия:
Фильтрация потока сообщений в реальном времени;
База данных фильтра должна обновляться не реже, чем рекомендовано производителем фильтра.
5.3 Тестирование обучаемых систем А. Длительность тестирования. При тестировании обучаемых пользователем систем (байесовских и им подобных) необходимо воспроизводить тот режим обучения, который будет использоваться при реальной эксплуатации. То есть - регулярное дообучение по пропущенному спаму и ложным срабатываниям. Это и есть штатный режим любой обучаемой пользователем системы.
Тестирование обучаемых систем должно производиться достаточное время - желательно 2-3 недели. Практика эксплуатации таких самообучающихся систем показывает, что в них может возникать эффект "избыточного обучения", при котором качество распознавания резко падает, поэтому крайне желательно проверить отсутствие этого эффекта еще на стадии тестирования.
Б. Наведенные эффекты. Если обучаемая система установлена после какого-то другого антиспам-фильтра, то при обучении и тестировании ее необходимо удалять все метки, проставляемые в сообщения первым фильтром.
В противном случае весьма вероятно, что обучаемая система обучится этим меткам и будет с успехом пользоваться "интеллектом" первого фильтра.
6. Наиболее частые ошибки при тестировании
Отсутствие общепринятых методик тестирования антиспам-систем приводит к тому, что при тестировании довольно часто допускают рассмотренный ниже ряд ошибок в методологии тестирования.
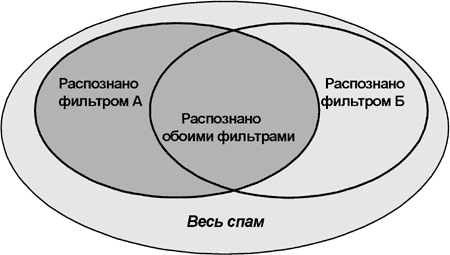
6.1 "Последовательное соединение" фильтров Достаточно часто используется тестирование методом подсчета "разности", при котором фильтр Б ставится на поток спама, получаемый на фильтре А.
Затем, если фильтр Б что-то пропускает из спама, обнаруженного фильтром А, то Б считается хуже, чем А. Действительно, А распознал "все", а Б - "не все".
Ошибка здесь в том, что, скорее всего, и фильтр А не распознает что-то из того, что фильтр Б признает спамом, но в односторонней цепочке =>А=>Б этого увидеть нельзя. Множества спама, распознаваемые обоими фильтрами, не вкладываются друг в друга, а имеют общее пересечение и "хвосты".
Очевидно, что для получения корректных результатов нужно одновременно (на том же потоке почты) собрать и зеркальную цепочку =>Б=>А - то есть проверку фильтра А на потоке спама, получаемом из фильтра Б.
В этом случае действительно будет возможно оценить все компоненты общей картины:
--- Спам-письма, которые улавливаются обоими фильтрами; --- Спам-письма, которые улавливаются только фильтром А или только фильтром Б; --- Одновременные ложные срабатывания обоих фильтров; --- Ложные срабатывания каждого фильтра по отдельности.
Только имея такую полную картину, можно обоснованно сравнивать качество распознавания антиспам-систем.
6.2 Пересылка (forward) сообщений на фильтр В силу особенностей почтового протокола, при пересылке сообщений теряются или искажаются следующие технические параметры сообщений:
--- IP-адрес посылающей стороны; --- Параметры SMTP-сессии (HELO, MAIL FROM); --- Заголовки письма (добавляется лишний Received). --- Если антиспам-фильтр тем или иным способом учитывает эти данные при анализе сообщений на спам, то результаты тестирования будут значительно отличаться от результатов будущей реальной эксплуатации (скорее всего, тесты с пересылкой покажут более низкие результаты распознавания).
При пересылке писем из распространенных почтовых клиентов (Outlook, Outlook Express) технические заголовки писем искажаются очень сильно, что делает практически невозможным распознавание спама по заголовкам.
6.3 Тестирование на фиксированных коллекциях Довольно часто антиспам-системы пытаются тестировать на фиксированных статических коллекциях (архивах) спама. Эти коллекции обычно получают тремя способами:
--- сбором спама на специальных адресах-ловушках (spamtraps), на которые в принципе не должна приходить нормальная почта; --- ручной сортировкой потока входящей корреспонденции; --- сортировкой входящей корреспонденции с помощью какой-нибудь другой антиспам-программы.
Независимо от способа получения коллекции, тестирование на коллекциях имеет следующие серьезные ограничения:
Невозможно полностью воспроизвести "окружение" при приходе письма. В любом случае, при тестировании на коллекции письмо заведомо пересылается на фильтр с другого IP-адреса; скорее всего - с другим SMTP HELO; с большой вероятностью - к заголовкам письма добавлены дополнительные поля Received. Это сильно снижает качество анализа спама фильтром. Антиспам-программы используют быстро меняющиеся во времени наборы данных. Содержимое системы DNS и RBL-списков, счетчики систем подсчета частотности (DCC, Razor и подобные), содержание статистических баз (для систем с самообучением), содержание баз правил и образцов (для систем, получающих обновления) меняются несколько раз в день, иногда - несколько раз в час или вообще каждую секунду (например, для списков RBL).
Воспроизвести все эти наборы данных в том же состоянии, в котором они были на момент прихода письма - невозможно, следовательно, результаты тестирования будут значительно отличаться от результатов реальной эксплуатации.
Таким образом, тестирование на любых фиксированных коллекциях даст результат, отличающийся от реального (результата фильтрации того же письма в момент его реального поступления) - вне зависимости от способа, которым была получена коллекция. Особенно будут искажены результаты тестирования фильтров с быстрым обновлением.
При этом есть и дополнительные проблемы, связанные с получением коллекций тем или иным способом.
А. Коллекции, полученные на спам-ловушках, отличаются тем, что поток спама на них отличается от "среднего спама, получаемого активным пользователем" - адреса-ловушки не ведут переписку в форумах, публичную деятельность и т.п. В результате такие адреса попадают в базы данных, как правило, в результате автоматического перебора по словарю или, в крайнем случае, получаются обходом сайтов (если эти адреса публиковались на сайтах).
В результате получаемый на ловушки спам статистически отличается от спама, рассылаемого по стандартным спамерским базам (например, на "бизнес-адреса Москвы").
Б. Коллекции, получаемые ручным отбором, обычно имеют небольшой размер (отобрать вручную даже несколько десятков тысяч сообщений - большая работа) и, как правило, наряду с "настоящим" спамом содержат также "нежелательную для пользователя" переписку, которая не является спамом (квитанции от почтовых систем, уведомления и так далее).
В. Коллекции, получаемые фильтрованием другими программами, содержат "спам с точки зрения другой программы", что, конечно, не имеет отношения к реальной жизни.
Таким образом, самое важное качество - скорость реакции фильтра - оценить на фиксированных ретроспективных коллекциях почты нельзя. На таких коллекциях можно оценить только схожесть методов работы разных антиспам-фильтров, а для правильной оценки качества фильтрации следует использовать методику, описанную выше в разделе "Оценка различий в работе фильтров".
6.4 Неверные обучающие выборки для обучаемых фильтров Наиболее частая ошибка при тестировании обучаемых пользователем фильтров - некорректно выбранная обучающая выборка при обучении.
А. Одна и та же выборка для обучения и тестирования. Наиболее грубой ошибкой является использование одной и той же выборки и для обучения, и для тестирования (уровень распознавания в результате будет резко завышенным). Именно такими некорректными условиями тестирования чаще всего объясняются рекламируемые производителями невероятные уровни распознавания наподобие 99,98%.
Б. Обучение на половине коллекции. Способ, который кажется "более корректным", - разделить весь архив спама на обучающую и тестирующую выборку - тоже не дает достоверных результатов. Обычно в таком архиве содержится много дублей спам-сообщений (одинаковое письмо, пришедшее много раз или на разные адреса). В результате эти дубли окажутся и в обучающей, и в тестирующей выборке и будут превосходно обнаруживаться - опять-таки давая сильно завышенную оценку качества.
Корректный способ тестирования обучаемых фильтров (в реальном времени с реальным дообучением) описан выше (см. раздел "Тестирование обучаемых систем").
Примечание: RBL - 'Realtime Blackhole List' - черный список IP-адресов, доступный по DNS-протоколу. Является наиболее распространенным антиспам-средством, наиболее частый способ использования - безусловное отвержение всей почты, приходящей с IP-адресов из списка.
Источник: lexa.ru Авторы: Алексей Тутубалин, Игорь Ашманов